Implementing Kernel Density Estimation - Univariate

Summary
Kernel Density Estimation approximates a probability density function from collected samples. In contrast to a histogram, we do not need first to discretise the data by placing it into bins, instead building a continuous estimate. Applied to height measurements of adults, for example, we obtain a continuous density describing the likelihood of each possible height.
This article will first introduce the concept of a Kernel as applied to smoothing data points before implementing it in the Julia programming language. Next, this implementation will be modified to calculate the Kernel Density Estimate of 1-dimensional data before exploring possibilities for determining an optimal bandwidth.
Kernel Smoothing
A Kernel function acts as a weighted measure of distance between objects. It is not restricted exclusively to points in a space - see, for example, the string kernel - it should, however, in most cases be both symmetric and non-negative. For example, a Kernel function operating on real numbers generally has the following form:
\[ K_{h}(x^*, \bm{x}_i) = D \left( \frac{ \left || \bm{x}_i - x^* \right || }{ h(x^*) } \right ) \]
where
- \(\bm{x}^* \in \mathbb{R}^p\) is the specific point for which we are calculating an estimate
- \(\bm{x}_i \in \mathbb{R}^p\) are the other points in the space
- \(\left || ... \right ||\) is a Norm, be that Euclidean or otherwise
- \(h(\bm{x}^*)\) determines the radius of the Kernel, or equivalently the weighting of a given comparison
- \(D(...)\) is a real-valued function
Several Kernels fitting this mould can be seen here.
Given a Kernel, we can create a continuous function that connects a set of points, i.e. smooths the data. In order to do this, we construct a local weighted average across a dataset. The form this average takes is a generalisation of the traditional weighted arithmetic mean,
\[ \bar{x} = \frac{\sum_{i = 1}^n w_i x_i}{\sum_{i = 1}^n w_i} \]
which, given \(n\) observations \(x_i\) and corresponding weights \(w_i\), constructs a global average of a given set of points.
The generalisation, named after Èlizbar Nadaraya and Geoffrey Watson, replaces the weights \(w_i\) with the result of the Kernel function producing the following form:
\[ \hat{Y} (x^*) = \frac{ \sum_{i=1}^n K_{h}(x^*, \bm{x}_i) Y(\bm{x}_i) }{ \sum_{i=1}^n K_{h}(x^*, \bm{x}_i) } \]
Here,
- \(Y(\bm{x}_i)\) returns the magnitude of the sample at \(\bm{x}_i\)
- and \(n\) is the number of samples available to build an estimate from

For example, given a Kernel function that weights an estimate via the Euclidean distance to its surrounding points, we expect something like the \(+\) for the point \(\bm{x}^*\) in the image above, as \(d1\) is much smaller than \(d2\) and \(d3\). Therefore, the point with the most influence on the estimate is the point directly to the left.
Gaussian Kernel Smoothing
We create the Gaussian Kernel from the above more general form by setting \(D(u)\) to \(\text{exp}( -1/2 u^2)\) and \(h(x^*)\) to \(\sigma\). In this case, the correct norm is the \(\text{L}_2\) or Euclidean norm.
\[ K_{\text{smoother}}(x^*, x) = \text{exp} \left ( - \frac{1}{2} \left ( \frac{ x - x^* }{\sigma} \right )^2 \right ) \]
Using this Kernel function and the Nadaraya-Watson estimator, we can then build an estimate for each point \(x^*\). The weighting contributed by each surrounding point falls off in a bell curve-like manner with increased distance. The red, green and yellow curves in the image below show this relative weighting as the \(\sigma\) value of the Kernel is varied.
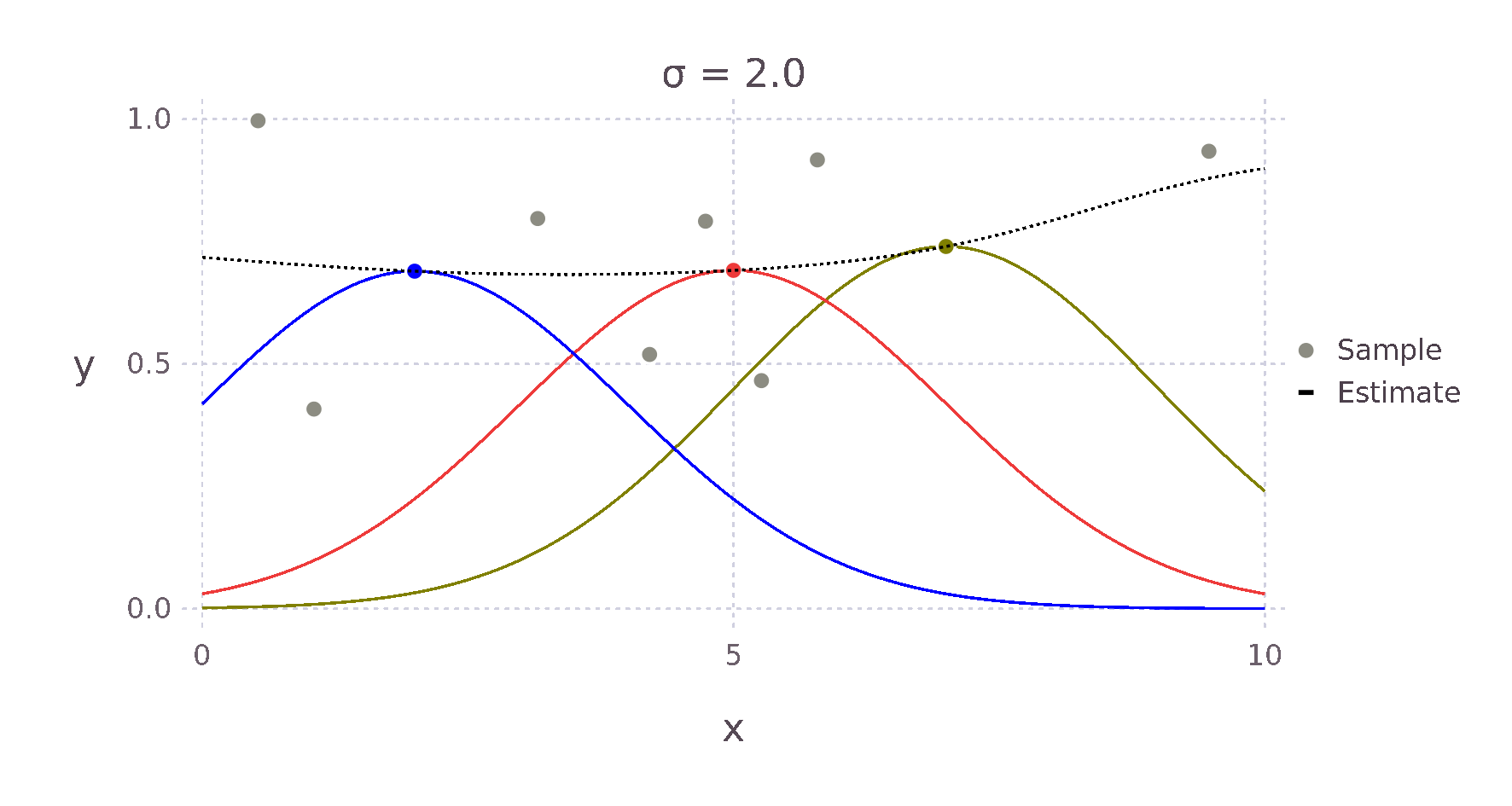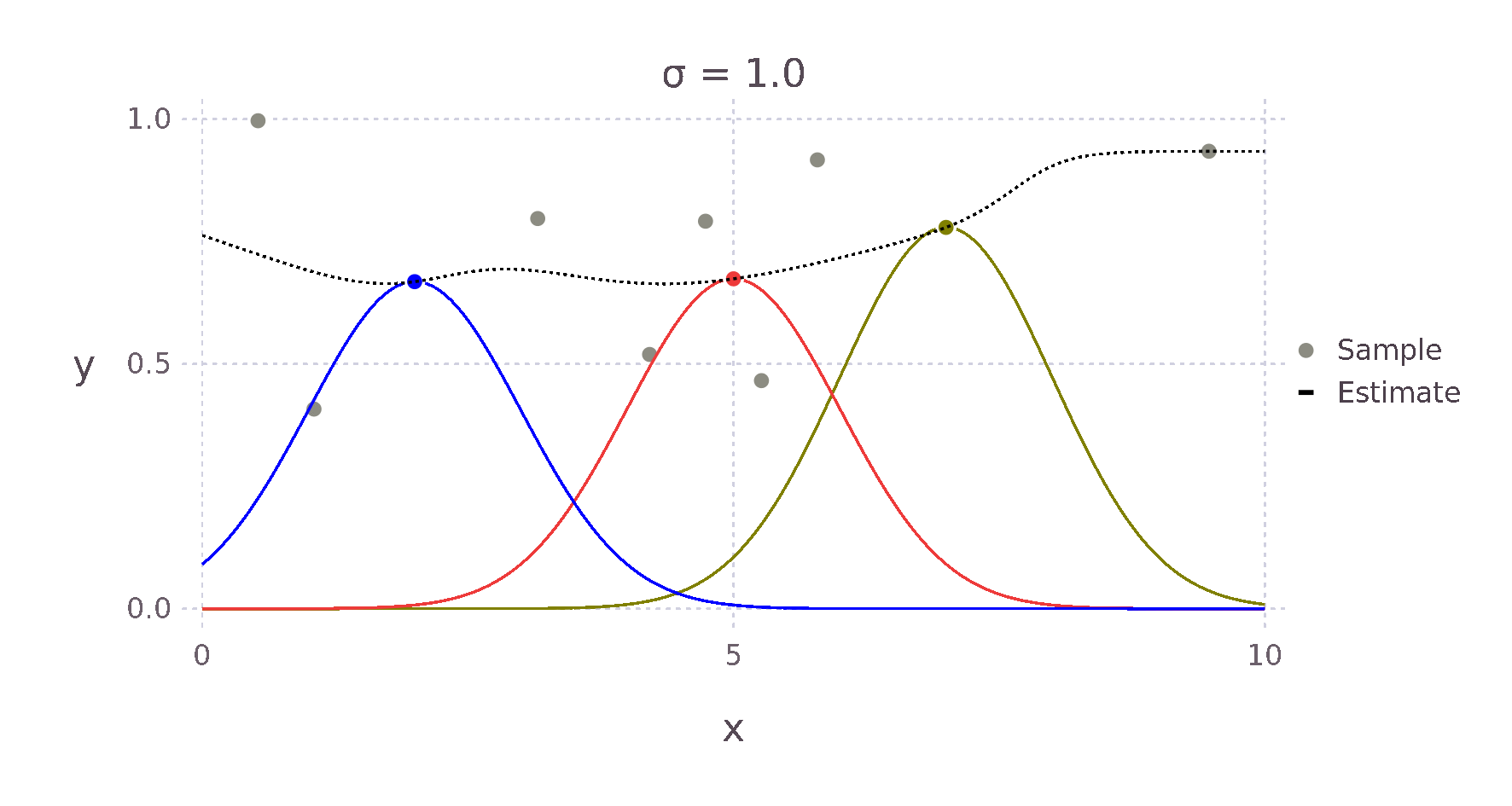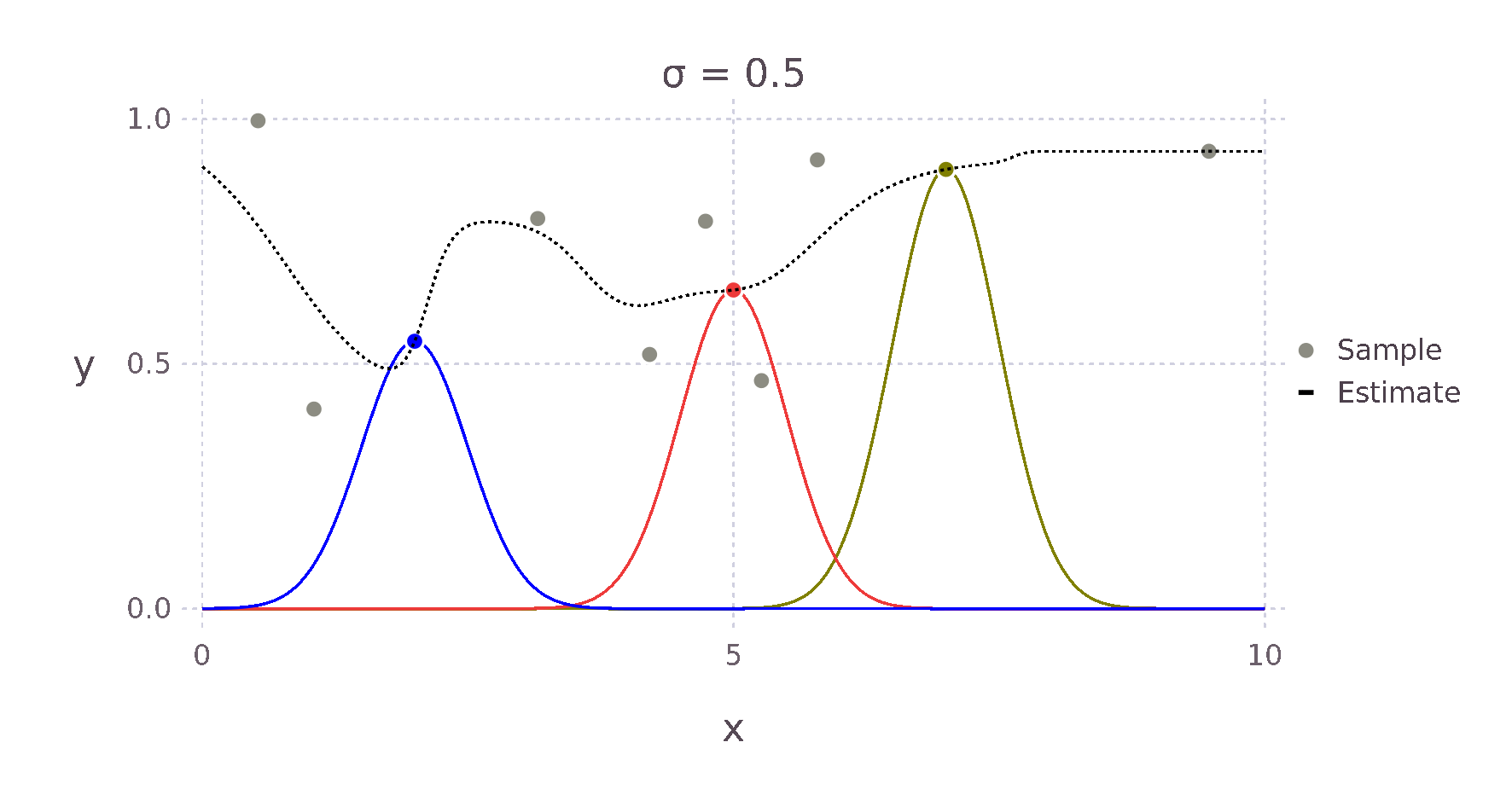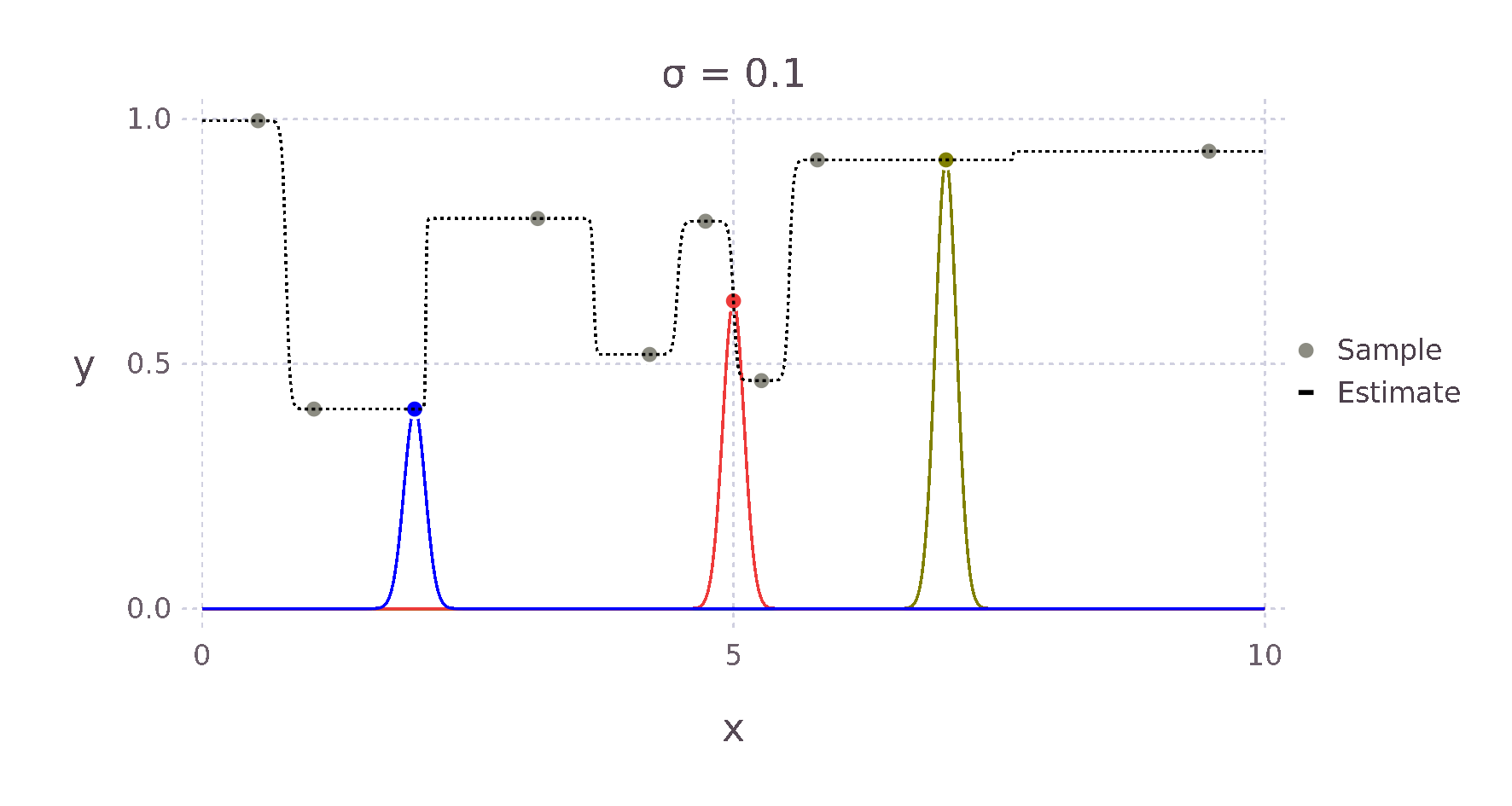
These two equations can be almost directly written as Julia code giving us the following implementation.
Ksmoother(x_star, x, σ) = ℯ^( - 1/2 * (x_star - xs)^2 / σ^2)
function NadarayaWatsonEstimate(x_star, xs, Ys, σ)
W = Ksmoother.(x_star, xs, σ)
sum( W .* Ys ) / sum( W )
endHaving chosen a value \(\sigma\), our estimate for a specific point \(x^*\) can then be found as follows
σ = 0.75
# Surrounding Points
x = [ 0, 4.21, 5.79, 7.37, 9.47 ]
Y = [ 0.03, 0.08, 0.93, 0.91, 0.99 ]
Yhat = NadarayaWatsonEstimate(x_star, x, Y, σ)Gaussian Kernel Density Estimate
The main difference between the smoother we constructed, and a density estimate is that we haven't ensured that the area under the curve integrates to \(1\). Our first step is to add the missing normalising term of the Gaussian normal density function to our Kernel from before, producing
\[ K_\sigma(x^*, x) = \frac{1}{\sigma \sqrt{2 \pi}} \text{exp} \left ( - \frac{1}{2} \left ( \frac{x^* - x}{\sigma} \right )^2 \right ) \]
or in Julia
K(x_star, x, σ) = 1/(σ * √(2*π)) * ℯ^( - 1/2 * (x_star - x)^2 / σ^2)Instead of the mean \(\mu\) typical of the definition, we have one of the samples, \(x\). In fact, to construct an estimate of our density, we build a mixture from \(n\) Gaussian distributions, with the mean of each being one of the samples \(x_i\). Observing this fact then leads to the equation for our probability density estimate.
\[ \hat{f}(x | \sigma, \bm{x}) = \frac{1}{n} \sum_i^n K_\sigma(x, \bm{x}_i) \]
In Julia we can write this as
f(x, σ, xs) = 1/length(xs) * sum(K.(x, xs, σ))We can similarly construct the cumulative density function estimate by taking the average of the cumulative density of each of the Gaussian distributions. The cumulative density of a single Gaussian, where \(\text{erf}\) is the error function, is as follows.
\[ \Phi(x | \mu, \sigma) = \frac{1}{2} \left [ 1 + \text{erf} \left ( \frac{x - \mu}{\sigma \sqrt{2}} \right) \right ] \]
As in the case of the probability density function, our estimate is created by averaging each of the cumulative density functions.
\[ \hat{\text{cdf}} (x| \sigma, \bm{x}) = \frac{1}{n} \sum_i^n \Phi(x | \bm{x}_i, \sigma) \]
By making use of the SpecialFunctions package, we implement these two equations in Julia.
using SpecialFunctions
Φ(x, μ, σ) = 1/2 * (1 + erf((x - μ) / (σ * √2)))
cdf(x, σ, xs) = 1/length(xs) * sum(Φ.(x, xs, σ))We can test these functions by generating samples from a known Gaussian distribution to see whether the estimates match.
using Distributions
μ = 4
σ = 2
true_distribution = Normal(μ, σ)
samples = rand(true_distribution, 50)
pdf_estimate = f
@show pdf(true_distribution, 2), pdf_estimate(2, σ, samples)
# (0.121, 0.115)
@show pdf(true_distribution, 3), pdf_estimate(3, σ, samples)
# (0.176, 0.141)
@show pdf(true_distribution, 5), pdf_estimate(5, σ, samples)
# (0.176, 0.137)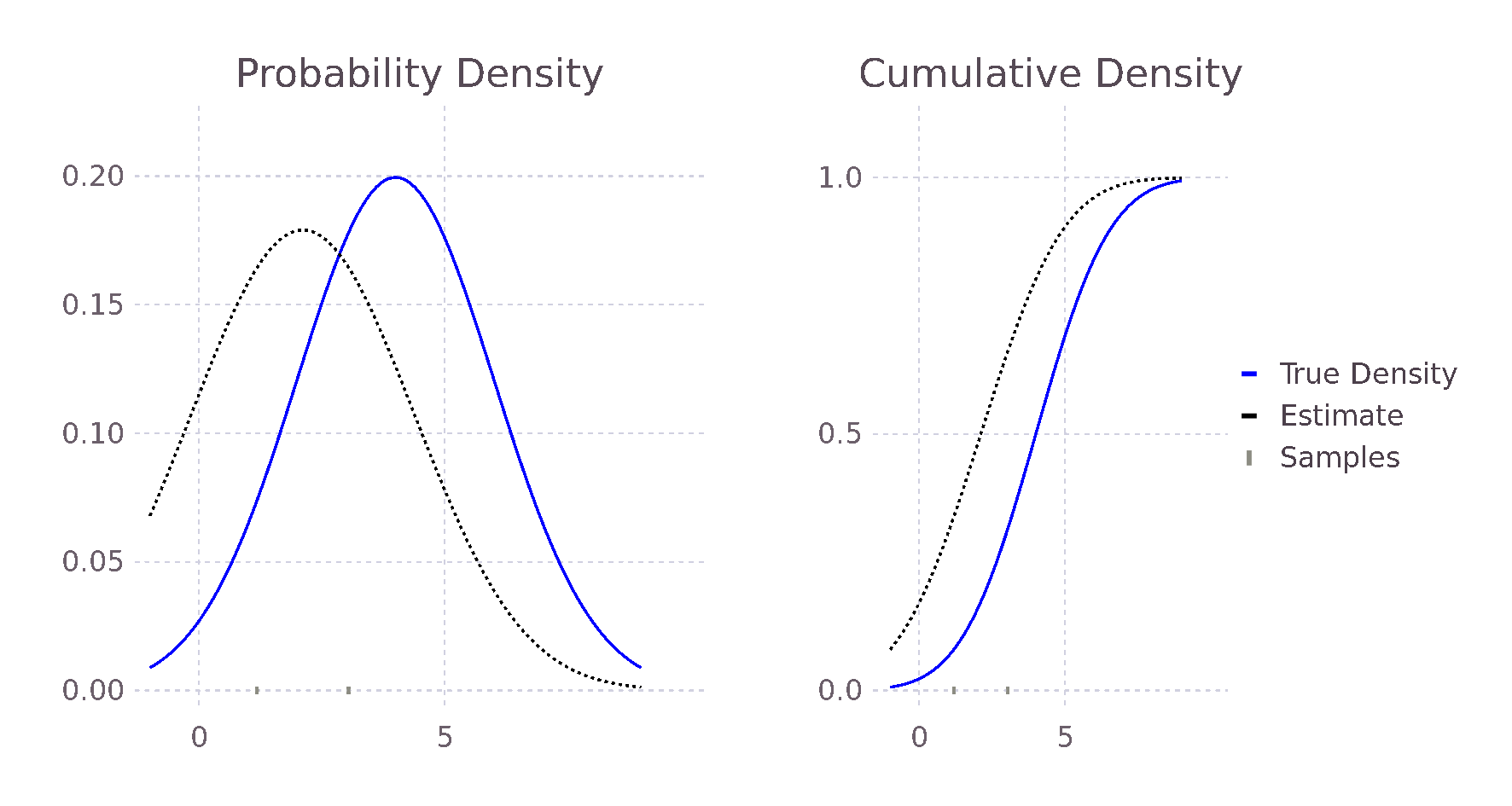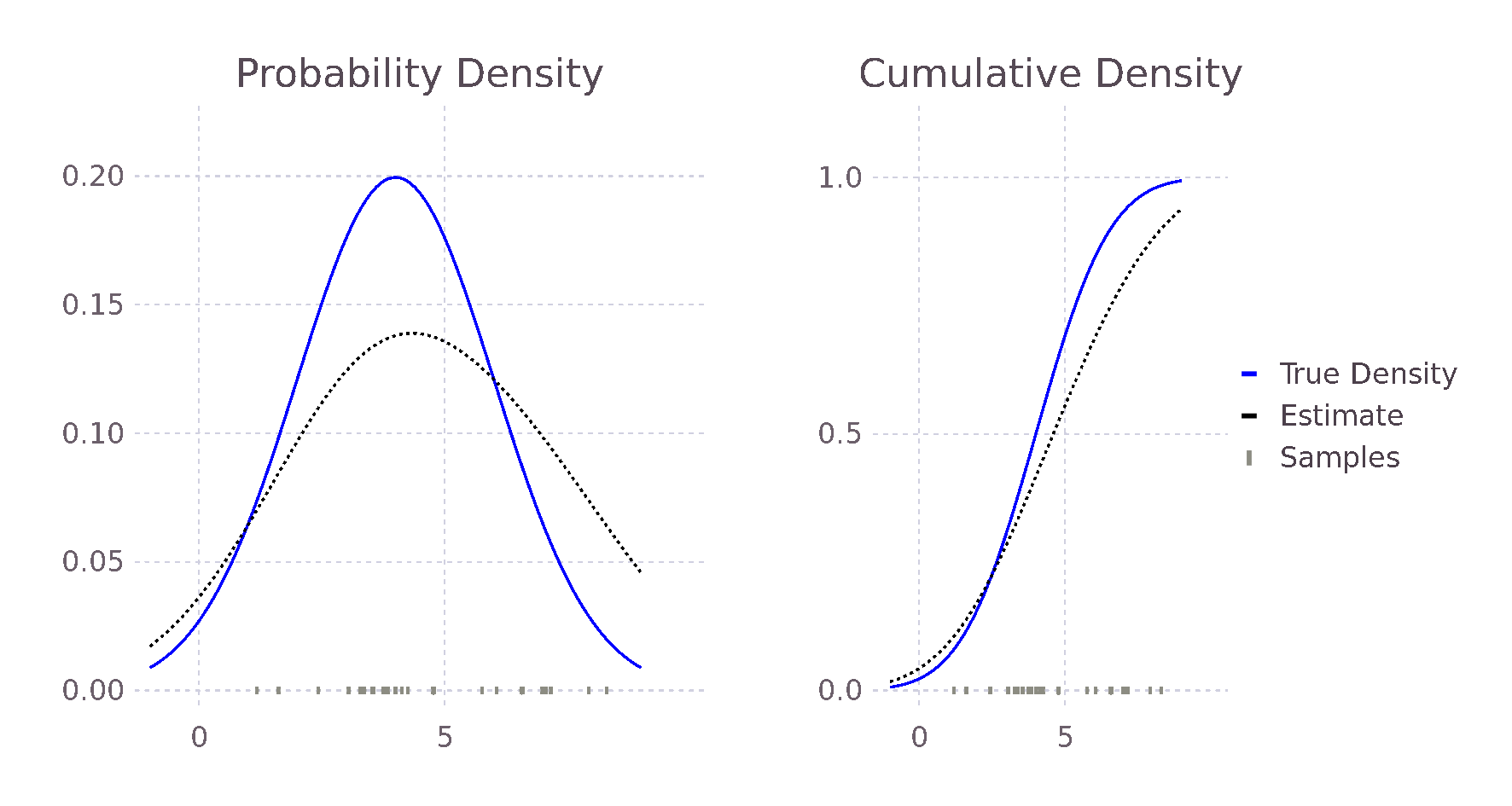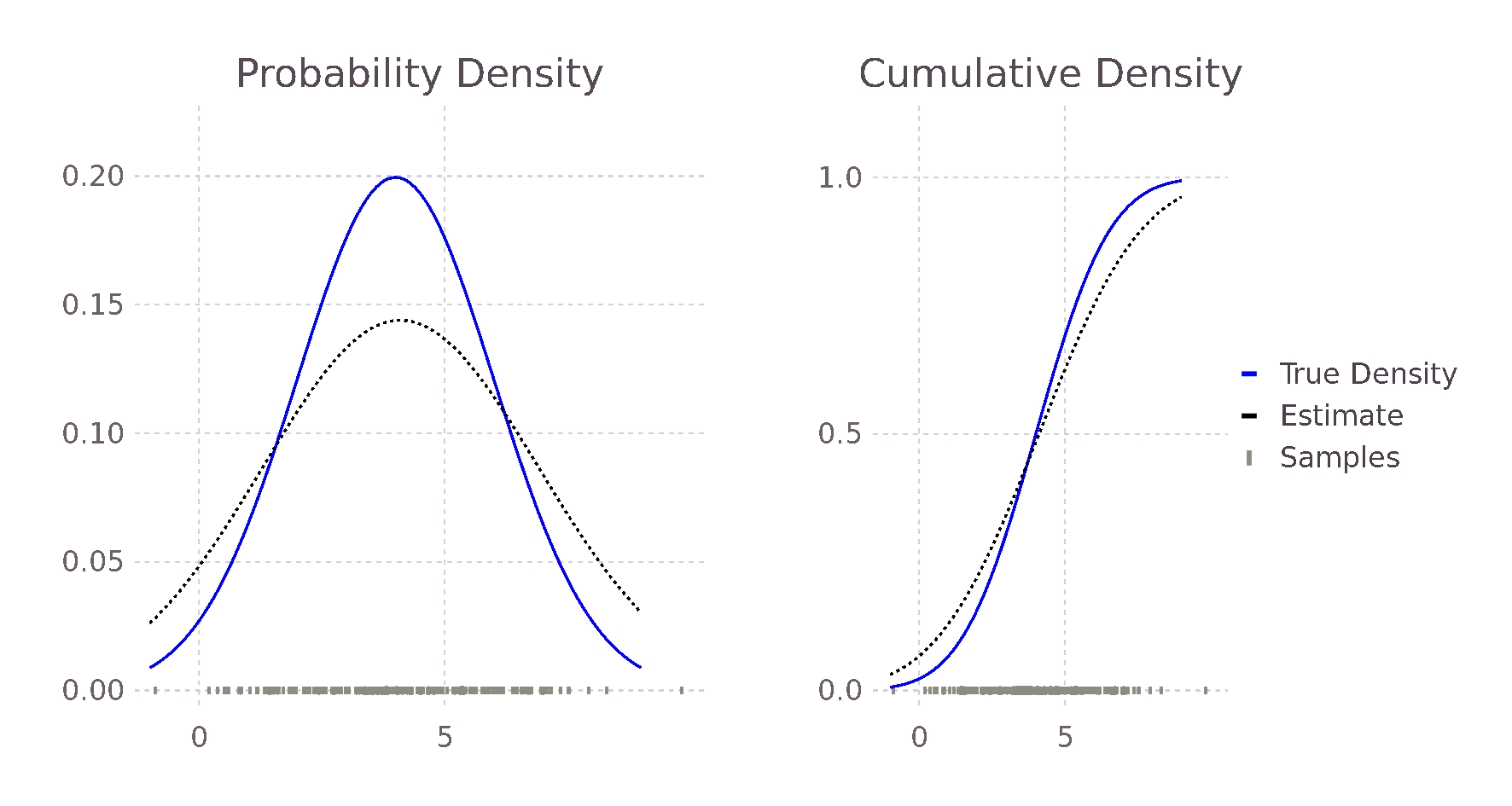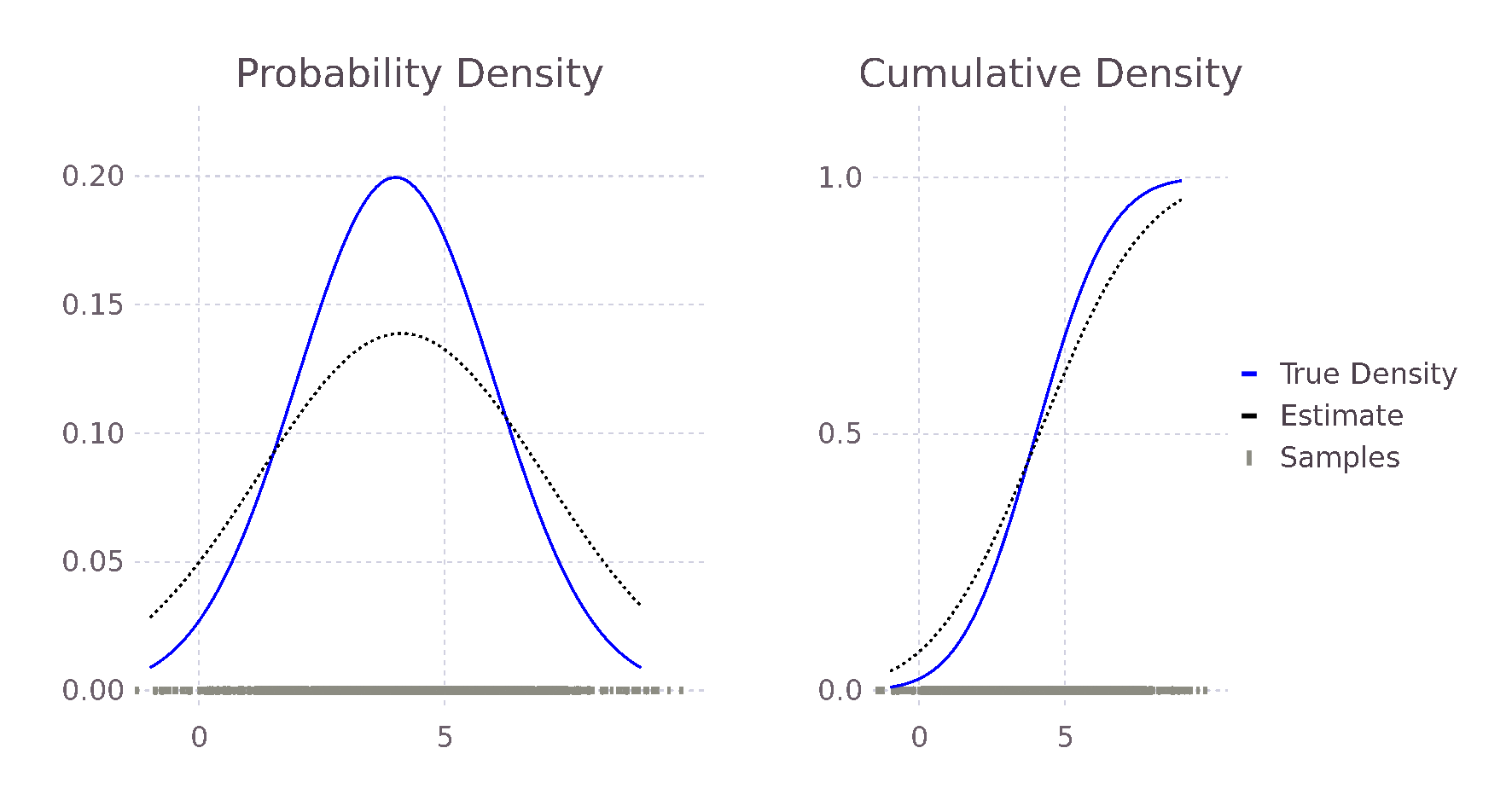
What becomes apparent when plotting the estimate and actual distributions is that the estimate does not match exactly even when the true variance is known and there are several samples. This is because the estimate is not a single density but an average of many.
Estimating Bandwidth
The discrepancy we have just seen suggests we need an alternative approach for determining our estimator's \(\sigma\) value. In the more general case, where we are not just considering the Gaussian kernel, this weighting is known as the bandwidth. It corresponds to the \(h(x^*)\) in our original, more general form above. There are two types of approaches for determining the bandwidth, cross-validation and rule-of-thumb. We will focus on the second here.
Many of the rule-of-thumb approaches start by attempting to minimise the Mean Integrated Square Error (MISE) but simplify its calculation by introducing estimates and simplifications. Given a true probability density function \(f\), and a kernel estimate \(\hat{f}\), the MISE is as follows.
\[\begin{aligned} \text{MISE}(\hat{f}) &= \int \text{E} \left[ \left( \hat{f}(x) - f(x) \right)^2 \right ] \text{d}x \\ &= \int \left( \text{E} \left [ \hat{f}(x) \right ] - f(x) \right )^2 \text{d}x + \int \text{var} \hat{f}(x) \text{d}x \end{aligned} \]
This can be understood as the sum of the integrated square bias and integrated variance. During this part of the derivation, we are not restricting ourselves exclusively to the Gaussian Kernel, so we continue with a slightly more general form for our estimate.
\[ \hat{f}(x) = \frac{1}{n} \sum_{i}^n \frac{K \left( \left ( x - y \right ) / h \right )}{h} \]
To fit this form of \(\hat{f}\) our Gaussian Kernel is defined
\[
K(u) = \frac{1}{\sqrt{2\pi}} \text{exp} \left ( - \frac{1}{2} u^2 \right )
\]
This results in the same form as we had above
\[\begin{aligned}
\frac{K \left( \left ( x - y \right ) / \sigma \right )}{\sigma} &= \frac{1}{\sigma \sqrt{2\pi}} \text{exp} \left ( - \frac{1}{2} \left( \frac{x -y}{\sigma} \right )^2 \right ) \\
&= K_\sigma(x, y)
\end{aligned}
\]
As a reminder, we require that our Kernel is symmetric, non-negative and as we use it for density estimation, it should integrate to \(1\).
To simplify the bias term we make use of the variable substitution \(y = x - hu\), \(\text{d}y = h \text{d}u\) and the Taylor expansion
\[ f(x - hu) = f(x) - h u f'(x) + \frac{1}{2}h^2 u^2 f''(x) + ... \]
to get
\[\begin{aligned} \text{bias} &= \text{E} \left [ \hat{f}(x) \right ] - f(x) \\ &= \int \frac{K \left( (x-y) / h \right )}{h} f(y) \text{d}y - f(x) \\ &= \int K(u) f(x - hu) \text{d}u - f(x) \\ &= \int K(u) \left ( f(x - hu) - f(x) \right ) \text{d}u \\ &= -h f'(x) \int u K(u) du + \frac{1}{2} h^2 f''(x) \int u^2 K(u)du + ... \end{aligned} \]
Due to the required symmetric property, we also have the equality
\[ \int_0^\infty u K(u) \text{d}u + \int_{-\infty}^0 u K(u) \text{d}u = 0 = \int u K(u) \text{d}u \]
as integrating either side of \(0\) results in the same absolute area, only the second side will be negative due to \(u\). Consequently, both sides of the integral cancel each other out.
Using this equality, we further simplify the bias term to
\[ \text{bias} = \frac{1}{2} h^2 f''(x) \int u^2 K(u)du + ... \]
The term \(\int u^2 K(u)du\) is the variance of the Kernel. We replacing it with the variable \(k\) for convenience. Now squaring and integrating the result nets us a second-degree approximation of the integrated square bias
\[ \frac{1}{4} h^4 k^2 \int f''(x)^2 dx \]
Recalling that variance can be expressed
\[ \text{var} \hat{f}(x) = \text{E} \left [ (X - \mu)^2 \right ] = \text{E} \left[ X^2 \right ] - \text{E} \left[ X \right ]^2 \]
we can use the same process on the variance term to simplify the remaining MISE term
\[\begin{aligned} \text{variance} &=\frac{1}{n} \int \frac{K \left ( \left ( x - y \right ) / h \right )^2}{h^2} f(y) \text{d}y - \frac{\left ( f(x) + \text{bias} \right )^2}{n} \\ &= \frac{1}{n h} \int f(x - h u) K (u)^2 \text{d}u - \frac{1}{n} \left ( f(x) + \text{bias} \right )^2 \\ &= \frac{1}{n h} \int \left( f(x) - htf'(x) + ... \right ) K (u)^2 \text{d}u - \frac{1}{n} \left ( f(x) + \text{bias} \right )^2 \end{aligned} \]
Typically, this is further simplified by considering only the case where the number of samples \(n\) is large and our bandwidth \(h\) is quite small. Under this assumption, the additional Taylor series terms approach zero relative to the initial \(f(x)\) term and the \(\frac{1}{n} \left ( f(x) + \text{bias} \right )^2\) approaches \(0\). Our variance is then
\[ \text{variance} \approx \frac{f(x)}{n h} \int K (u)^2 \text{d}u \]
Raising this term to the power of two and integrating over the \(f(x)\) term, which being a probability distribution integrates to one, gives us our integrated variance estimate
\[ \int \text{variance } \text{d}x \approx \frac{1}{nh} \int K(u)^2 \text{d}u \]
Together these terms build the Asymptotic Mean Integrated Square Error (AMISE) approximation, used in many bandwidth rule-of-thumb approaches.
\[ \text{AMISE}(h) = \frac{1}{nh} \int K(u)^2 \text{d}u + \frac{1}{4} h^4 k^2 \int f''(x)^2 k dx \]
In the literature this is often shorted to \(\frac{R(K)}{nh} + \frac{h^4 k^2 R(f'')}{4}\), where \(R(g) = \int g(x)^2 \text{d}x\).
We can then find an optimal bandwidth \(h\) by deriving our approximation with respect to \(h\) and equating it with \(0\).
\[\begin{aligned} \frac{\text{d}}{\text{d}h} \text{AMISE}(h) & = \frac{\text{d}}{\text{d}h} \frac{R(K)}{nh} + \frac{\text{d}}{\text{d}h} \frac{h^4 k^2 R(f'')}{4} \\ 0 &= - \frac{R(K)}{nh^2} + \frac{4 h^3 k^2 R(f'')}{4} \\ h^3 k^2 R(f'') &= \frac{R(K)}{nh^2} \\ h^5 &= \frac{R(K)}{k^2 R(f'')n} \\ h &= \left ( \frac{R(K)}{k^2 R(f'')n} \right ) ^{1/5} \end{aligned} \]
A more concise derivation of this approximation can be found in both (Silverman 1998, pages 36-40) and (Wand 1994, pages 19-22).
Optimal Bandwidth For Univariate Gaussian
Hoping to improve our Julia implementation above, we follow Silverman's treatment in (Silverman 1998, pages 45-48) and use this approximation to estimate the optimal \(h\) in the case of a Gaussian Kernel while under the assumption that the true density is a Gaussian distribution.
Starting with the \(R(K)\) term, we integrate over the square of our Gaussian Kernel.
\[\begin{aligned} R(K) &= \int \left ( \frac{1}{\sqrt{2\pi}} \text{exp} \left ( - \frac{1}{2} x^2 \right ) \right)^2 \text{d}x \\ &= \frac{1}{2 \pi} \int \left ( \text{exp} \left ( - \frac{1}{2} x^2 \right ) \right)^2 \text{d}x \\ &= \frac{\sqrt{\pi}}{2 \pi} \\ &= \frac{1}{2\sqrt{\pi}} \end{aligned} \]
Next, using our assumption that the true distribution is Gaussian, i.e. that \(f = \frac{1}{\sigma \sqrt{2 \pi}} \text{exp} \left( - \frac{1}{2} \frac{x^2}{\sigma^2} \right )\), we can solve for the \(R(f'')\) term.
\[\begin{aligned} R(f'') &= \int \left( \frac{\text{d}^2}{\text{d}x} \frac{1}{\sigma \sqrt{2 \pi}} \text{exp} \left( - \frac{1}{2} \frac{x^2}{\sigma^2} \right ) \right )^2 \text{d} x \\ &= \frac{1}{\sigma^{10} 2 \pi} \int \left( (x^2 - \sigma^2) \text{exp} \left( - \frac{1}{2} \frac{x^2}{\sigma^2} \right ) \right )^2 \text{d} x \\ &= \frac{1}{\sigma^{10} 2 \pi} \left( \frac{3 \sqrt{\pi} \sigma^5 }{4} \right ) \\ &= \frac{3}{8 \sigma^{5} \sqrt{\pi}} \end{aligned} \]
Remembering that \(k\) is the variance of our Kernel, in this case, equal to \(1\) as our Kernel is a standard Gaussian, our approximate optimal bandwidth is
\[\begin{aligned} h_{gaussian} &= (2 \sqrt{\pi})^{-1/5} \left ( \frac{3}{8 \sigma^{5} \sqrt{\pi}} \right )^{-1/5} (1^2 n)^{-1/5} \\ &= \left ( \frac{8}{6} \right )^{1/5} \sigma n^{-1/5} \\ &\approx 1.06 \sigma n^{-1/5} \end{aligned} \]
We can now implement this approximation in Julia, equating \(\sigma^2\) with an unbiased estimate of the variance of our samplesThe unbiased variance can be calculated as follows
\[
\begin{aligned}
\bar{x} &= \frac{\sum_i^n x_i}{n} \\
s^2 &= \frac{n^{-1} \sum_i^n (x_i - \bar{x})^2}{1 - n^{-1}}
\end{aligned}
\]
where \(1 - n^{-1}\) is the bias correction term
.
function h_est_gaussian(samples)
μ = sum(samples) / length(samples)
unbiased_variance = sum((samples .- μ) .^ 2) / ( length(samples) - 1 )
1.06 * √(unbiased_variance) * length(samples) ^ (-1 / 5)
endComparing this new estimate with our previous estimate and the true probability, we see an improvement in the predicted values. This is because the bandwidth of the Kernels is smaller, causing less smoothing and allowing for a larger range of predicted values.
μ = 4
σ = 2
true_distribution = Normal(μ, σ)
samples = rand(true_distribution, 50)
pdf_estimate = f
pdf_estimate_gaus_opt_h(x, samples) = f(x, h_est_gaussian(samples), samples)
@show pdf(true_distribution, 2),
pdf_estimate(2, σ, samples),
pdf_estimate_gaus_opt_h(2, samples)
# (0.121, 0.115, 0.111)
@show pdf(true_distribution, 3),
pdf_estimate(3, σ, samples),
pdf_estimate_gaus_opt_h(3, samples)
# (0.176, 0.141, 0.185)
@show pdf(true_distribution, 5),
pdf_estimate(5, σ, samples),
pdf_estimate_gaus_opt_h(5, samples)
# (0.176, 0.137, 0.173)
@show h_est_gaussian(samples)
# 0.907
In the same way, we could formulate an approximately optimal bandwidth for all potential density functions \(f\), assuming we can find \(f\)'s second derivative. We do not, however, in general, know the true distribution \(f\); our motivation to use Kernel density estimation in place of directly fitting a distribution. The true distribution may be multimodal or skewed heavily, causing over-smoothing. Silverman's now ubiquitous Rule of Thumb takes the previously derived optimal \(h_{gaussian}\) and tries to account for some of these possibilities. His first suggestion is to use the interquartile range (IQR) when it is smaller than the standard deviation of the data. Therefore, in the case of skewed distributions, fewer samples will influence the estimate at each point, reducing overall smoothing and allowing for a more locally defined estimate. In other words, we reduce the influence of our choosing a Gaussian Kernel when it seems less likely that the data follows a Gaussian distribution. Following similar reasoning, he also suggests reducing the \(1.06\) term to \(0.9\) with experiments showing improvement when \(f\) is skewed or bimodal with marginal degradation in the case of a Gaussian. The result of these modifications is Silverman's Rule of Thumb
\[ h = 0.9 \text{ min} \left ( \sigma , \frac{IQR}{1.34} \right ) n^{-1/5} \]
(Silverman 1998, page 48) In the case of a standard Gaussian distribution, the IQR is approximately \(1.34\sigma\)
In Julia, we can write this as follows, again employing an unbiased estimate of our data's variance
using StatsBase: quantile, Weights
function h_est_silverman(samples)
μ = sum(samples) / length(samples)
unbiased_variance = sum((samples .- μ) .^ 2) / ( length(samples) - 1 )
(q1, q3) = quantile(samples, [0.25, 0.75])
IQR = q3 - q1
0.9 * min( √(unbiased_variance) , IQR / 1.34) * length(samples) ^ (-1 / 5)
end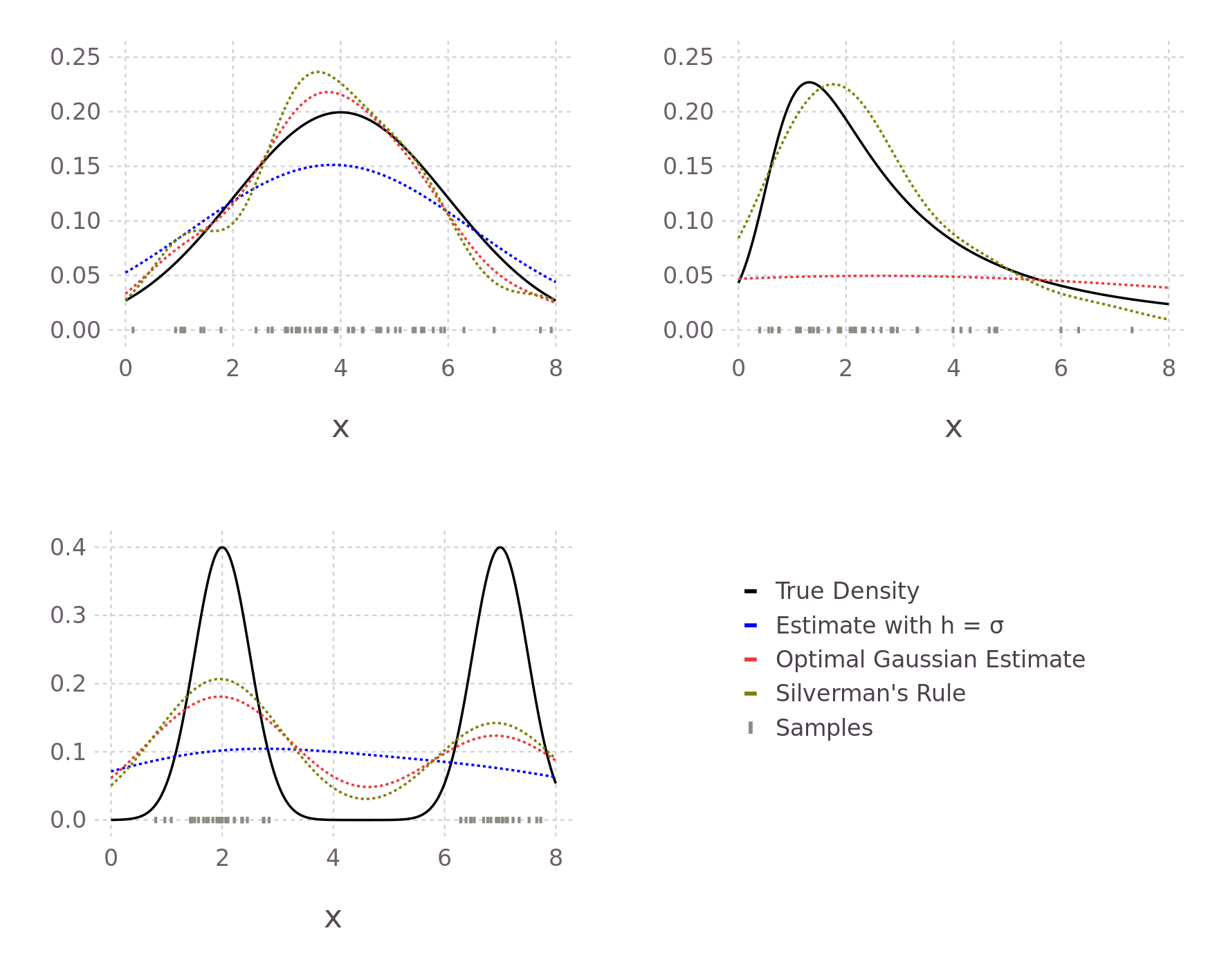
Instead of making assumptions about the true distribution \(f\), we can opt for a nonparametric approach. One such method is explored in (Sheather and Jones 1991). In the paper, the authors also proceed from the AMISE and, through a somewhat more involved derivation, reach the following result (equation 12 in the paper), similar to our above approximately optimal \(h\) form, but with the \(R(f'')\) term where we made assumptions about the true density modified.
\[ \left ( \frac{R(K)}{n k^2 \hat{S}_D(\hat{\alpha}_2(h))} \right)^{\frac{1}{5}} - h = 0 \]
where
\[\begin{aligned} \hat{S}_D(\alpha) &= \frac{1}{\alpha^5 n(n-1)} \sum_i^n \sum_j^n \phi^{\text{iv}} \left ( \frac{X_i-X_j}{\alpha} \right ) \\ \hat{T}_D(b) &= - \frac{1}{b^7 n(n-1)} \sum_i^n \sum_j^n \phi^{\text{vi}} \left( \frac{X_i-X_j}{b} \right ) \\ \hat{\alpha}_2(h) &= 1.357 \left ( \frac{\hat{S}_D(\alpha)}{\hat{T}_D(b)} \right )^{1/7} h^{5/7} \\ a &= \frac{0.920 \times \text{IQR}}{n^{1/7}} \\ b &= \frac{0.912 \times IQR}{n^{1/9}} \end{aligned} \]
In contrast to Silverman's Rule of Thumb, this approach additionally considers an estimate of the third derivative of our true density \(f\) and requires we calculate the fourth (\(\phi^{\text{iv}}\)) and sixth (\(\phi^{\text{vi}}\)) derivative of our chosen Kernel function.
Continuing our example with the Gaussian Kernel, these derivatives would be
\[ \begin{aligned} \phi^{\text{iv}} &= \frac{\text{d}^4}{\text{d}u^4} K(u) = \frac{u^4 - 6u^2 + 3}{\sqrt{2 \pi}} \text{exp} \left ( - \frac{1}{2} u^2 \right ) \\ \phi^{\text{vi}} &= \frac{\text{d}^6}{\text{d}u^6} K(u) = \frac{u^6 - 15u^4 + 45u^2 - 15}{\sqrt{2 \pi}} \text{exp} \left ( - \frac{1}{2} u^2 \right ) \\ \end{aligned} \]
It is now necessary for us to search for a bandwidth \(h\) that minimises the equation. Instead of implementing a solver ourselves, we can use the Julia Optim package.
using Optim
function h_est_sheatherjones(samples)
n = length(samples)
# 4th and 6th derivatives of the Kernel
# ϕ is the standard normal density
ϕIV(u) = (u^4 - 6*u^2 + 3) * 1/√(2π) * ℯ^(-1/2 * u^2)
ϕVI(u) = (u^6 - 15*u^4 + 45*u^2 - 15) * 1/√(2π) * ℯ^(-1/2 * u^2)
(q1, q3) = quantile(samples, [0.25, 0.75])
IQR = q3 - q1
a = 0.92 * IQR * n ^ (-1 / 7)
b = 0.912 * IQR * n ^ (-1 / 9)
# Only calculate half of the distances as each side is symmetric
# storing in a bottom triangular matrix
samplediffs = zeros(Int(n*(n-1)/2))
idx = 1
for r in 1:n, c in 1:r-1
# (r-1) * (r-2) ÷ 2 + c
samplediffs[idx] = samples[r] - samples[c]
idx += 1
end
# Multiplied by 2 as only have half of the distance matrix
TDb = -2 / (n * (n-1) * b^7) * sum( ϕVI.(samplediffs ./ b) )
SDα = 2 / (n * (n-1) * a^5) * sum( ϕIV.(samplediffs ./ a) )
function absolute_error(h)
h = h[1]
α2h = 1.357 * ( SDα / TDb ) ^ (1/7) * h ^ (5/7)
SDα2 = 2 / (n * (n-1) * α2h^5) * sum( ϕIV.(samplediffs ./ α2h) )
# Want == 0
abs( (1 / (2 * √π * SDα2 * n)) ^ (1/5) - h )
end
result = optimize(
absolute_error,
0, # Search Min Bound
h_est_silverman(samples) * 1000, # Search Max Bound
Brent()
)
@assert Optim.converged(result)
h = Optim.minimizer(result)[1]
end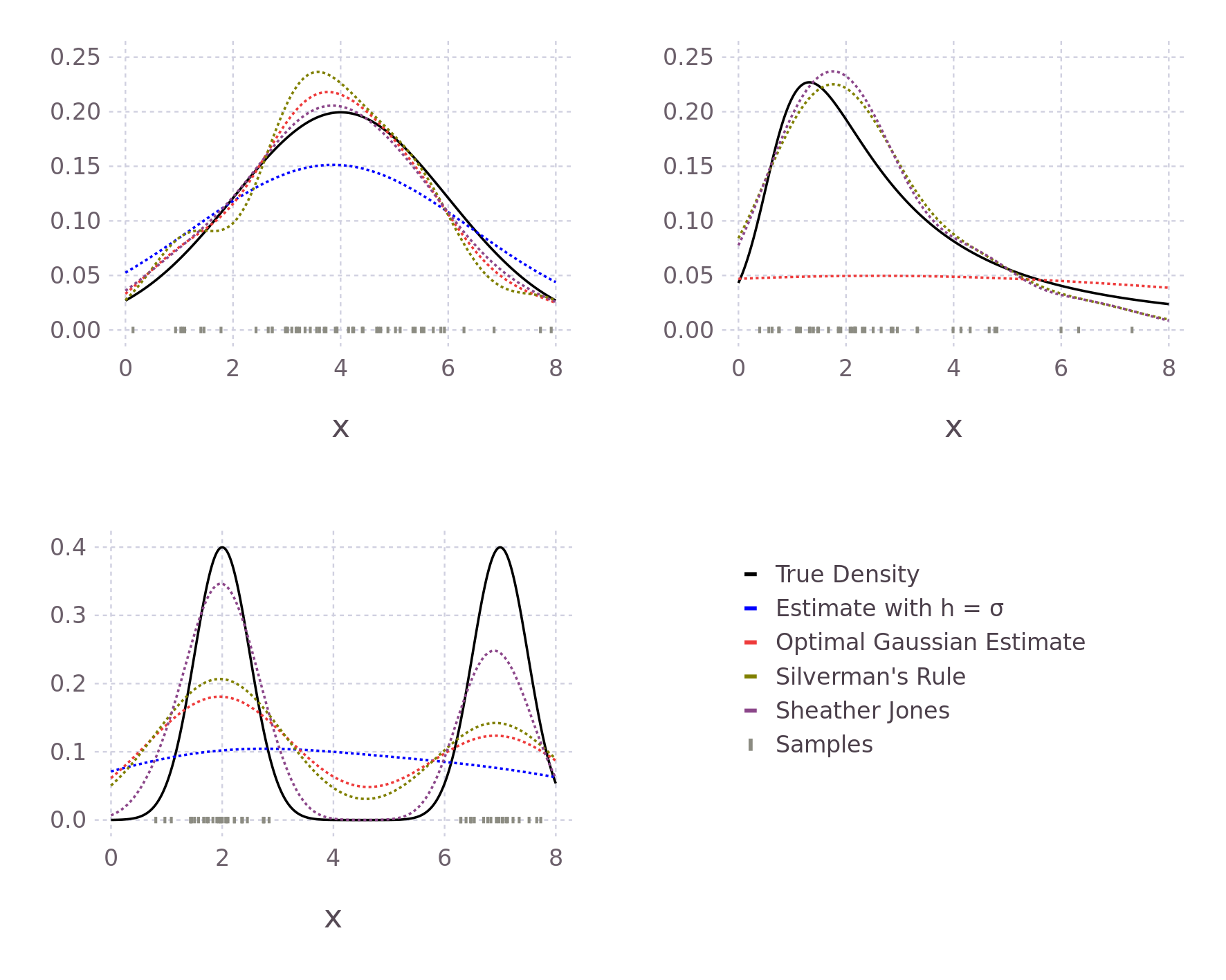
Working With Weighted Samples
Sometimes we want the influence of each sample on the result to differ. For example, when constructing a customer spending model, we could weight each transaction with the customer's transaction frequency. This would reduce the bias of high-volume customers on the model.
There are two types of weights; integer count weights and fractional proportions (our example is the second). We can still create an unbiased estimate via Bessel correction in the first case, as in the implementations above. In the proportion case, however, we have no information about the total size of our sample.This topic has provoked discussion on the statics StachExchange. See Bias correction in weighted variance, Weighted Variance, one more time and Correct equation for weighted unbiased sample covariance.
We may, therefore, choose to forego applying the correction or instead attempt to approximate the number of samples. For example, via Kish's Rule of Thumb.
\[ n_{\text{eff}} = \frac{\left ( \sum_i^n w_i \right ) ^2}{\sum_i^n w_i^2} \]
When all weights are equal
\[
n_{\text{eff}} = \frac{\left ( \sum_i^n \frac{1}{n} \right ) ^2}{\sum_i^n \frac{1}{n^2}} = \frac{1^2}{\frac{n}{n^2}} = n
\]
If we have integer-type weights or choose to use Kish's Rule of Thumb, we end up with an analogous term to the Bessel correction for individual equally weighted samples. The \(n\) in the \(1 - n^{-1}\) correction term is effectively replaced by \(n_{\text{eff}}\) giving us the following form for an unbiased weighted variance. The Wikipedia page has a full derivation.
\[ \begin{aligned} \bar{x}_{\text{weighted}} &= \frac{\sum_i^n w_i \times x_i}{\sum_i^n w_i} \\ s_{\text{weighted}} &= \frac{ \left ( \sum_i^n w_i \right )^{-1} \left( \sum_i^n w_i (x_i - \bar{x_i})^2 \right ) }{ 1 - n_{\text{eff}}^{-1} } \\ \end{aligned} \]
If all of the samples have a weight of one, we recover the traditional equation for non-biased variance, as both \(\sum_i^n w_i\) and \(n_{\text{eff}}\) will equal \(n\).
Using this definition we modify Silverman's Rule of Thumb for weighted samples so that bandwidth estimates are still possible.
using StatsBase: quantile, Weights
function h_est_silverman(samples, ws)
μ = sum(ws .* samples) / sum(ws)
neff = sum(ws)^2 / sum(ws .^ 2)
unbiased_variance = 1 / sum(ws) * sum(ws .* (samples .- μ) .^ 2) / ( 1 - 1 / neff )
# We also calculate a weighted IQR
(q1, q3) = quantile(samples, Weights(ws), [0.25, 0.75])
IQR = q3 - q1
0.9 * min( √(unbiased_variance) , IQR / 1.34) * length(samples) ^ (-1 / 5)
endThe weighted IQR can also make use of Kish's Rule of Thumb. A wonderful outline can be found here.
A more in depth exploration of this modification to Silverman's Rule of Thumb can be found in (Wang and Wang 2007). Unfortunately, the Sheather-Jones method can't be modified as easily for weighted samples.
To account for the weights in our density estimate, we must similarly modify our estimator definition. We have the following form: analogous to the difference between a mean and a weighted mean.
\[ \hat{f}(x | \sigma, \bm{x}, \bm{w}) = \frac{ \sum_i^n \bm{w}_i K_\sigma(x, \bm{x}_i) }{\sum_i^n \bm{w}_i} \]
In Julia we can write this as
f(x, σ, xs, ws) = sum(ws .* K.(x, xs, σ)) / sum(ws)